Research Interest
I am primarily interested in embodied intelligence, especially robot control via deep reinforcement learning (including interactive and inverse reinforcement learning, imitation learning, transfer learning) and its application in robotics (including social robot, autonomous underwater robot, manipulator and mobile robot), machine learning, human-robot interaction.
Projects (as Principal Investigator)
- Interactive Reinforcement Learning in Underwater Robot, Natural Science Foundation of China (NSFC), 298k Chinese Yuan
- ******, 1 million Chinese Yuan
- Multimodal Social Reinforcement Learning, Honda Research Institute Japan, 2016-present, 27.5 million Japanese Yen
- Deep Interactive Reinforcement Learning, Natural Science Foundation of Shandong Province, 140k Chinese Yuan

Interactive Learning of Social Behaviors with Haru Robot
This project is collaborated with researchers at Honda Research Institute Japan. We study methods on robot learning social behaviors by interacting with people of the general public, e.g., human-centered reinforcement learning, learning from demonstration etc. The objective of this project is to personalize the Haru robot through social interactions with human users. For example, we are developing methods allowing Haru to automatically detect the human user’s emoji and select an appropriate Harumoji based on the human user’s preference.
Relevant publications: ICRA 2021, IEEE Trans. on Human Machine Systems 2019, RO-MAN 2018 2020 2022

Transferring Policy of Deep Reinforcement Learning from Simulation to Reality
This project aims to develop methods for sim2real transferring control policy of deep reinforcement learning with a robot manipulator.
Relevant publications: IROS 2021

Deep Reinforcement Learning for Intelligent Control of Autonomous Underwater Vehicle
This project aims to develop deep reinforcement learning methods for robust and safe control of autonomous underwater vehicle.
Relevant publications: Ocean Engineering 2021

Autonomous Driving via Deep Reinforcement Learning
This project aims to develop deep reinforcement learning methods for autonomous and safe control of mobile robots.

Learning from Implicit Human Reward
This project studies how an agent learns from implicit human reward—facial expressions. We investigated whether telling trainers to use facial expression as a channel to train the agent has effect on trainer behavior and agent performance and whether the effect differs for different age groups and genders. We also studied the importance of the agent’s competitive feedback but now in a group consisting of closely related trainers, e.g., family members and close friends, in a much broad range of ages and genders. Finally, we tried to find the correlation between facial expression and explicit human reward and train a model of them to predict human reward signals based on the trainer’s facial expressions. The ultimate objective is to use this prediction as a reward signal to train the agent when no explicit feedback is provided by a human trainer.
Relevant publications: AAMAS 2015 2016, JAAMAS 2020

Leveraging Agent’s Socio-Competitive Feedback
We investigated the influence of the agent’s socio-competitive feedback on the human trainer’s training behavior and the agent’s learning with our Facebook app “Intelligent Tetris”. The agent’s socio-competitive feedback substantially increases the engagement of the participants in the game task and improves the agents’ performance, even though the participants do not directly play the game but instead train the agent to do so. Moreover, making this feedback active further induces more subjects to train the agents longer but does not further improve agent performance.
Relevant publications: AAMAS 2014, ICDL-EpiRob 2014, JAAMAS 2018
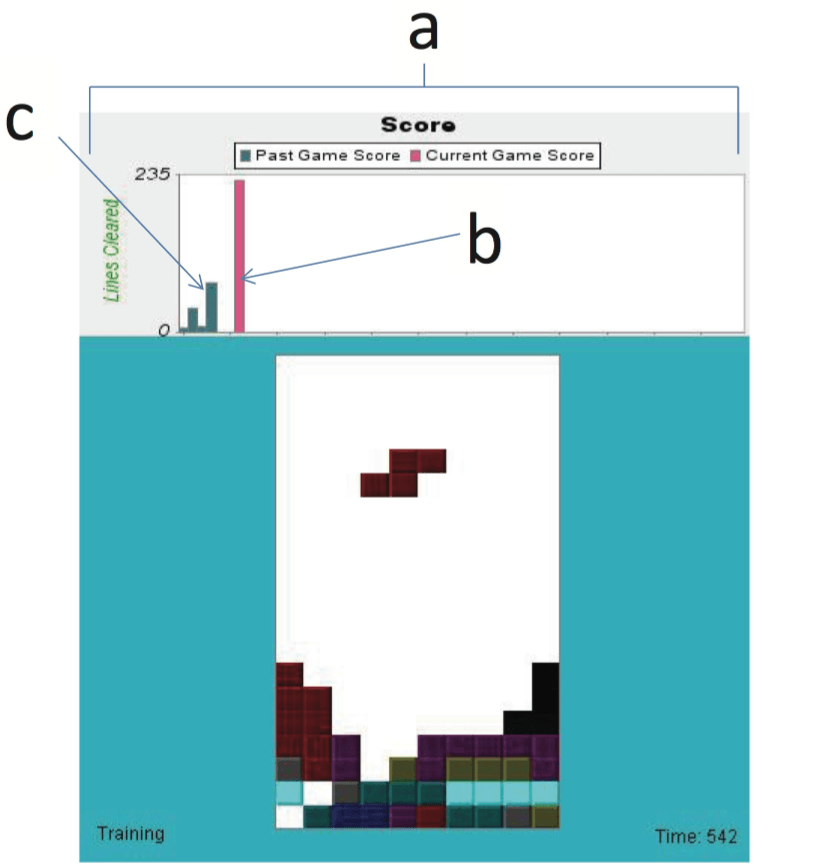
Agent’s Informative Behavior Affects the Trainer
Using TAMER agents, we studied how changes to the training interface affected trainers. Specifically, we investigated the agent’s two kinds of informative feedback: one provides information on the agent’s uncertainty, the other on its performance. Both informative feedback induced trainers to give more feedback. However, the agent’s performance increases only in response to the addition of performance-oriented information, not by sharing uncertainty levels. Analysis showed that trainers could be distracted by the agent sharing its uncertainty levels about its actions, giving poor feedback for the sake of reducing the agent’s uncertainty without improving performance.
Relevant publications: AAMAS 2013, JAAMAS 2016
